内容来自于《机器学习》
性能度量
聚类性能度量亦称为有效性指标(validity index)。
聚类性能度量大致有两类。一类是将聚类结果与某个参考模型进行比较,成为外部指标,另一类是直接考察聚类结果而不利用任何参考模型,称为内部指标。
聚类性能度量外部指标:
- Jaccard 系数:
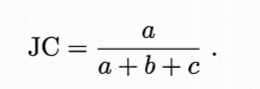
- FM(Fowlkes and Mallows Index)指数:
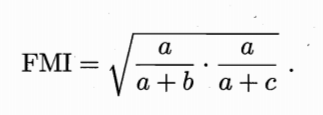
- Rand 指数:
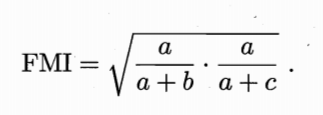
上述性能度量的结果值均在[0,1]区间,值越大越好。
聚类性能度量内部指标:

DB指数(Davies-Bouldin Index,DBI):
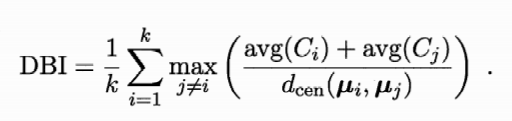
Dunn指数(Dunn Index,DI):
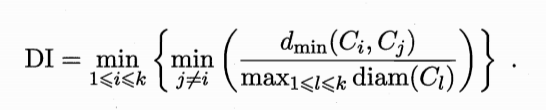
DBI值越小越好,DI越大越好
距离计算
对函数dist(.,.),若是一个距离度量,需要满足基本性质:

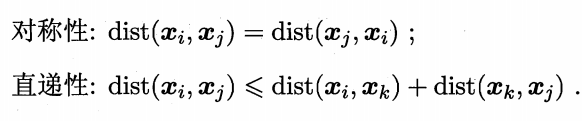
闵可夫斯基距离(Minkowski distance):
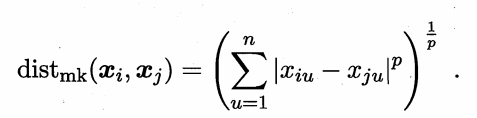
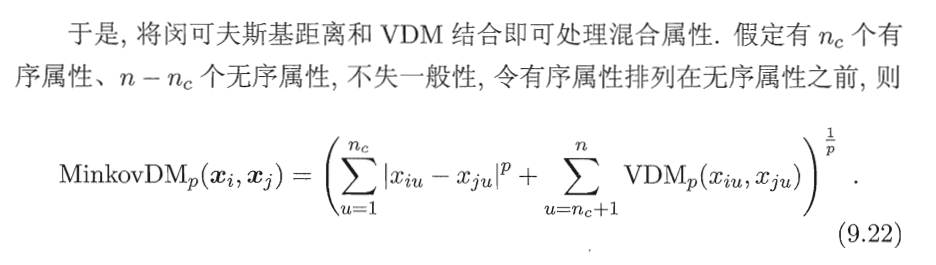
连续属性和离散属性
有序属性和无序属性

原型聚类
原型聚类亦称为基于原型的聚类(prototype-based clustering)。此类算法假设聚类结构能通过一组原型刻画,在现实聚类任务中极为常用。
k均值 k-means算法:

学习向量量化 Learning Vector Quantization, LVQ:试图找到一组原型向量来刻画聚类结构,但与一般聚类算法不同的是,LVQ假设数据样本带有类别标记,学习过程利用养着的这些监督信息来辅助聚类。

高斯混合聚类:采用概率模型来表达聚类原型。
密度聚类
基于密度的聚类 density-based clustering,此类算法假设聚类结构能通过样本分布的紧密程度确定。
DBSCAN是一种著名的密度聚类算法,基于一组邻域参数刻画样本分布的紧密程度。

层次聚类
层次聚类 hierarchical clustering 试图在不同层次对数据集进行划分,从而形成树形的聚类结构。数据集的划分可采用 自底向上的聚合策略,也可采用自顶向下的分拆策略。
AGNES是一种采用自底向上聚合策略的层次聚类算法。
