内容来自于《机器学习》
未标记样本
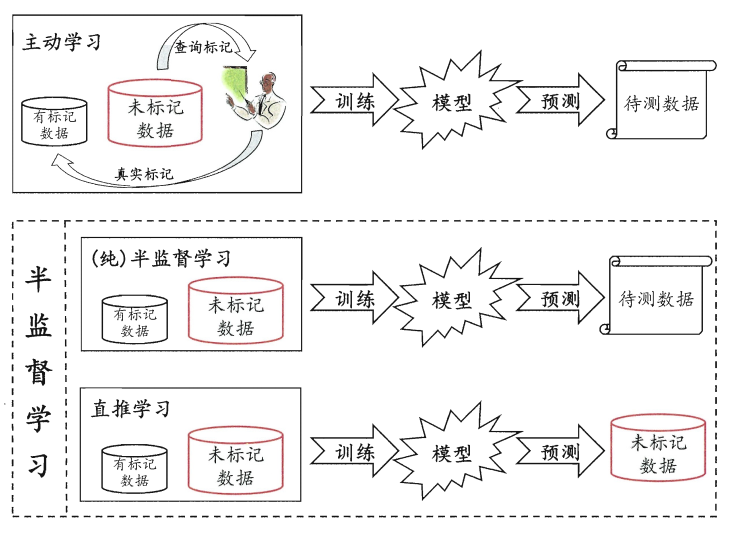
主动学习 active learning 其目标是使用尽量少的查询获得尽量好的性能。
让学习器不依赖外界交互,自动地利用未标记样本来提升学习性能,就是半监督学习 semi-supervised learning。
聚类假设 cluster assumption,假设数据存在簇结构,同一个簇的样本属于同一个类别。
流形假设 manifold assumption,假设数据分布在一个流形结构上,邻近的样本拥有相似的输出值。
生成式方法
生成式方法 generative methods 是直接基于生成式模型的方法。此类方法假设所有数据都是由同一个潜在的模型生成的。这个假设使得我们能通过潜在模型的参数将未标记数据与学习目标联系起来,而未标记数据则看作模型的缺失参数,通常可基于EM算法进行极大似然估计求解。此类方法的区别主要在与生成式模型的假设,不同的模型假设将产生不同的方法。
半监督SVM
半监督支持向量机 semi-supervised support vector machine, S3VM
低密度分隔 low-density separation
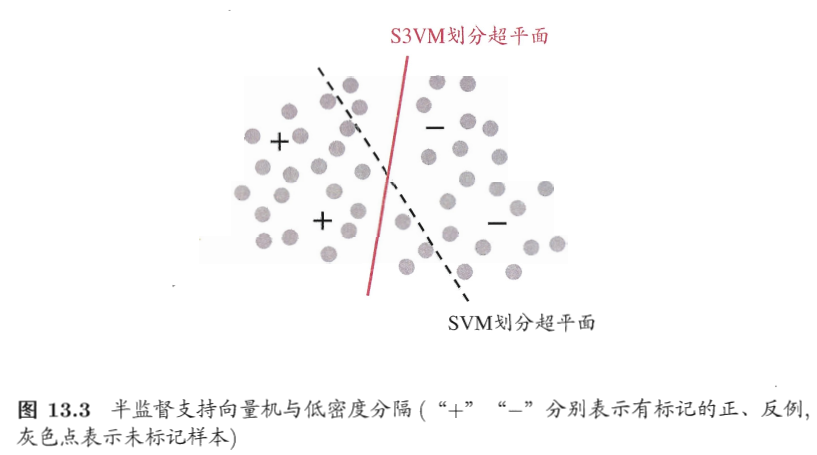
半监督支持向量机中最著名的是TSVM(Transductive Support Vector Machine).TSVM针对二分类问题。TSVM视图考虑未标记样本进行各种可能的标记指派(label assignment),即尝试将每个未标记样本分别作为正例或反例,然后在所有这些结果中,寻求一个在所有样本(包括有标记样本和进行了标记指派的未标记样本)上间隔最大化的划分超平面。一旦划分超平面得以确定,未标记样本的最终标记指派就是其预测结果。

半监督SVM研究的一个重点是如何设计出高效的优化求解策略,由此发展出很多方法,如基于图核(graph kernel)函数梯度下降的LDS,基于标记的均值估计的meanS3VM等。
图半监督学习
亲和矩阵(affinity matrix).
高斯函数带宽参数。
图半监督学习方法在概念上相当清晰,且易于通过对所涉及矩阵运算的分析来探索算法性质。但此类算法上的缺陷也相当明显。首先是在存储开销上,若样本数为O(m),则算法中设计的矩阵规模为O(m*m)。这使得此类算法很难直接处理大规模数据;另一方面,由于构图过程仅能考虑训练样本集,难以判知新样本在图中的位置,因此,在接收到新样本时,或是将其加入原数据集对图进行重构并重新进行标记传播,或是引入额外的预测机制,例如将Dt和经标记传播后得到标记的Du合并作为训练集,另外训练一个学习器例如支持向量机来对新样本进行预测。
基于分歧的方法
基于分歧的方法(disagreement-based methods)使用多学习器,而学习器之间的分歧对未标记数据的利用至关重要。
协同训练 co-training 是此类方法的重要代表,最初是针对多视图multi-view数据设计的,因此也被看做多视图学习multi-view learning的代表。
相容性 compatibility
协同训练正是很好地利用了多视图的相容互补性。
协同训练可以有效提升弱分类器的性能。

半监督聚类
聚类任务中获得的监督信息大致有两种类型,第一种类型是必连must-link与勿连cannot-link约束,前者是指样本必属于同一个簇,后者是指样本必不属于同一个簇,第二种类型的监督信息则是少了的标记样本。
约束k均值算法 constrained k-means
约束种子k均值算法 constrained seed k-means